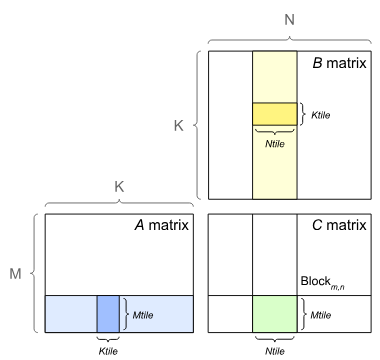
GPUs implement GEMMs by partitioning the output matrix into tiles, which are then assigned to thread blocks.
Each thread block computes its output tile by stepping through the K dimension in tiles, loading the required values from the A and B matrices, and multiplying and accumulating them into the output.
Better Performance using tensor cores
Tensor Cores depend on NVIDIA library versions. Performance is better when equivalent matrix dimensions M, N, and K are aligned to== multiples of 16 bytes== (or 128 bytes on A100). With NVIDIA cuBLAS versions before 11.0 or NVIDIA cuDNN versions before 7.6.3, this is a requirement to use Tensor Cores;
Decide the tiling size
While multiple tiling strategies are available,larger tiles have more data reuse, allowing them to use less bandwidth and be more efficient than smaller tiles. On the other hand, for a problem of a given size, using larger tiles will generate fewer tiles to run in parallel, which can potentially lead to under-utilization of the GPU.