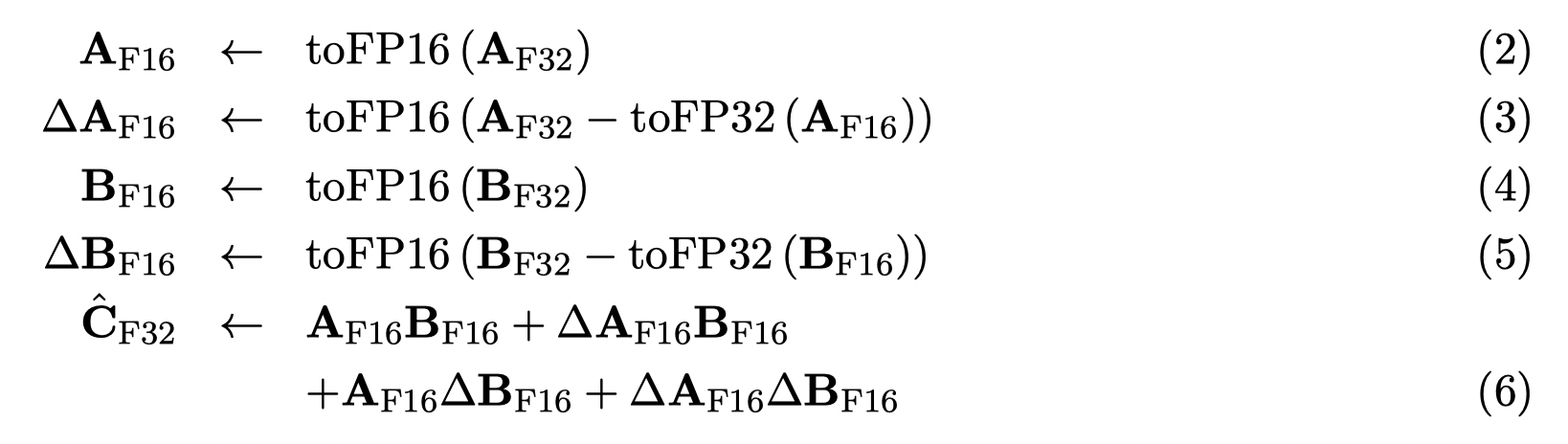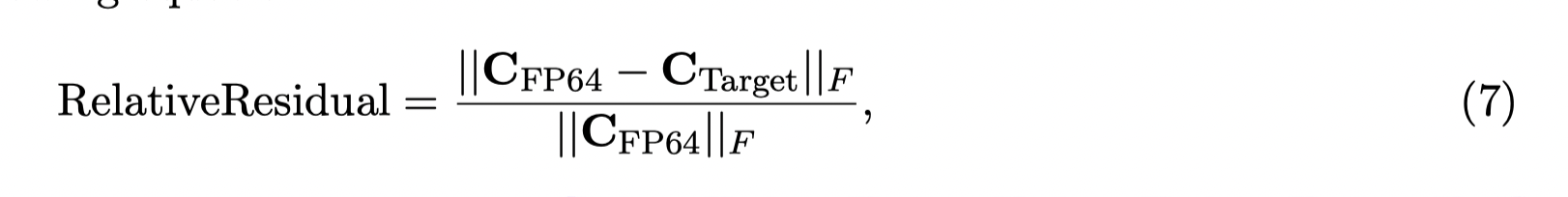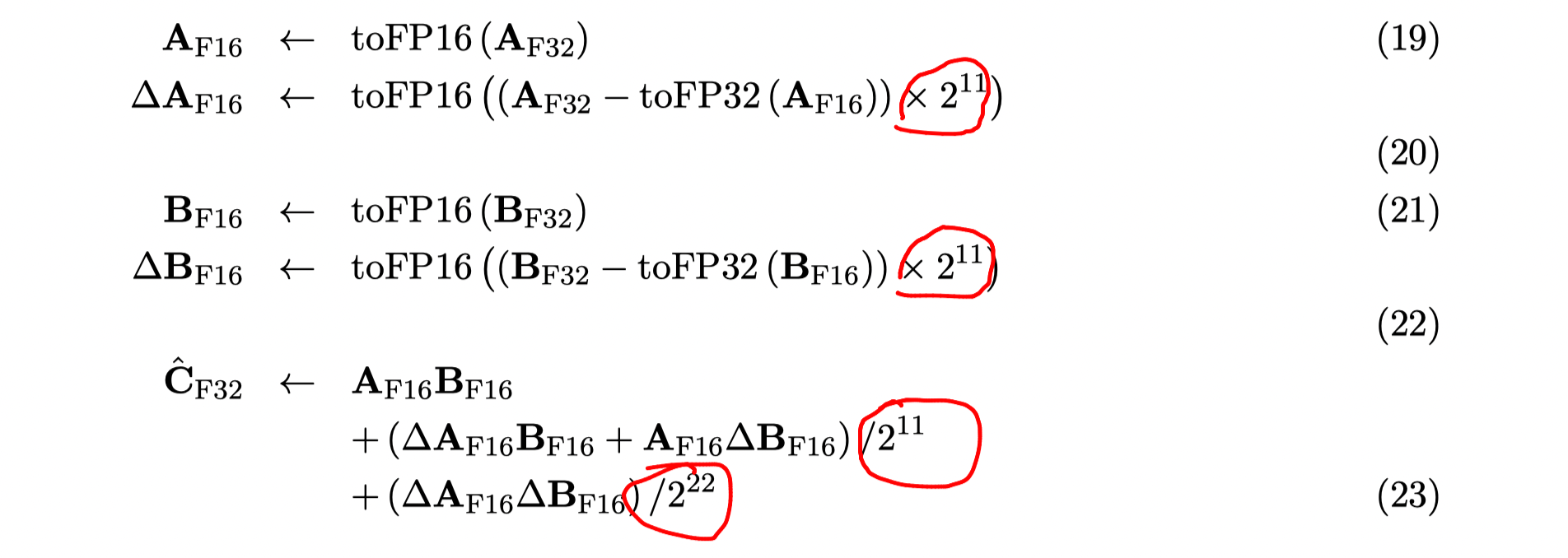Recovering single precision accuracy from Tensor Cores while surpassing the FP32 theoretical peak performance -- Hiroyuki Ootomo, Rio Yokota
Summary
This paper achieves the full fp32 precision recovering by improving Markidis‘s correction algorithm
Pre knowledge
Tensor cores is to compute $$D = A\times B + C $$ Hence, before going to tensor cores, A and B should be converted to FP16 or TF32. The accumulator will add C, which is a FP32 matrix. The final result is a FP32 matrix.
Note
The conversion loss is what Markidis‘s et al. consider mainly.
Markidis‘s correction algorithm
Algorithm
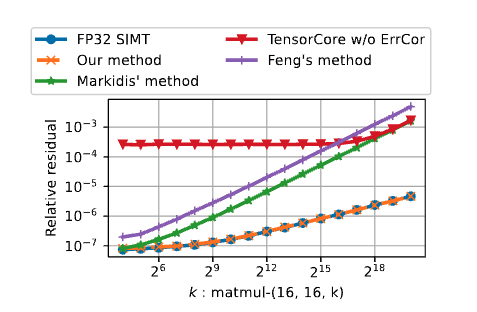
Accurate?
Evaluation metric
Accuracy Evaluation metric where is the reference matrix using FP64 to compute, i.e.
Power consumption is one important aspect need to be considered when using half precision algorithm.
In recent year, the real machines of quantum computer have been developed and tried to be shown quantum supremacy, that they compute certain tasks that (classical) supercomputers are not be able to compute in realistic time. Moreover, since they have low power consumption [2], energy efficiency is becoming an important metric when evaluating quantum supremacy. For instance, qFlex is a quantum computer simulator based on tensor network contraction using single-precision complex matrix-matrix multiplication, where the power consumption of each component was reported during its simulation on Summit V100 GPUs [28]. Although they have considered to use FP16 and Tensor Cores in their simulation, they decided not to use it since FP16 has less exponent than FP32 and insufficient to use.