NVIDIA GPU Performance Background
Take AWAYs
Architecture
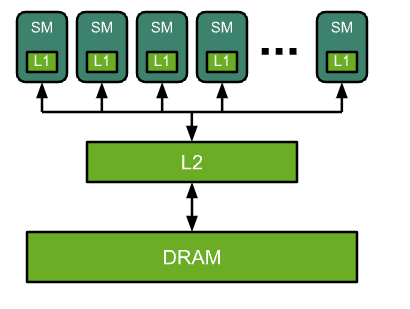
The GPU is a highly parallel processor architecture, composed of processing elements and a memory hierarchy. At a high level, NVIDIA® GPUs consist of a number of Streaming Multiprocessors (SMs), on-chip L2 cache, and high-bandwidth DRAM. Arithmetic and other instructions are executed by the SMs; data and code are accessed from DRAM via the L2 cache.
Tensor cores v.s. CUDA cors
When math operations cannot be formulated in terms of matrix blocks they are executed in other CUDA cores. For example, the element-wise addition of two half-precision tensors would be performed by CUDA cores, rather than Tensor Cores.
Performance
Performance of a function on a given processor is limited by one of the following three factors:
- memory bandwidth,
- math bandwidth and
- latency.
Memory limited and math limited
time is spent in accessing memory, time is spent performing math operations. If we further assume that memory and math portions of different threads can be overlapped, the total time for the function is . The longer of the two times demonstrates what limits performance: If math time is longer we say that a function is math limited, if memory time is longer then it is memory limited.
Memory time
Memory time is equal to the number of bytes accessed in memory divided by the processor’s memory bandwidth.
Math Time
Math time is equal to the number of operations divided by the processor’s math bandwidth.
Arithmetic intensity
ops:byte ratio
Thus, an algorithm is math limited on a given processor if the algorithm’s arithmetic intensity is higher than the processor’s ops:byte ratio. Conversely, an algorithm is memory limited if its arithmetic intensity is lower than the processor’s ops:byte ratio.
Latency
However, if the workload is not large enough, or does not have sufficient parallelism, the processor will be under-utilized and performance will be limited by latency.