Programming tensor cores using nvcuda-wmma
- Link: the code are are analyzing is: https://leimao.github.io/blog/NVIDIA-Tensor-Core-Programming/ and https://developer.nvidia.com/blog/programming-tensor-cores-cuda-9/
Background
Matrix Multiplication Background
Tiled Matrix Multiplication -- CUDA implementation
Chatgpt answer
https://chat.openai.com/share/cfd09f70-3b82-423e-a91f-3c096e658e3d
Take aways
Understand how the work is distributed!!
Unlike Tiled Matrix Multiplication -- CUDA implementation, wmma is operating on warp. That means
We just write wmma in one thread of a warp, and it will cooperate other threads in a warp. In other words, the __global__ wmma_kernel are executed in one thread of each warp. (As a comparison, codes of kernel in Tiled Matrix Multiplication -- CUDA implementation operate on each thread)
This is super important to understand How blockDim, gridDim are defined, how to index the elements in the matrix in each thread (__global__ kernel function)
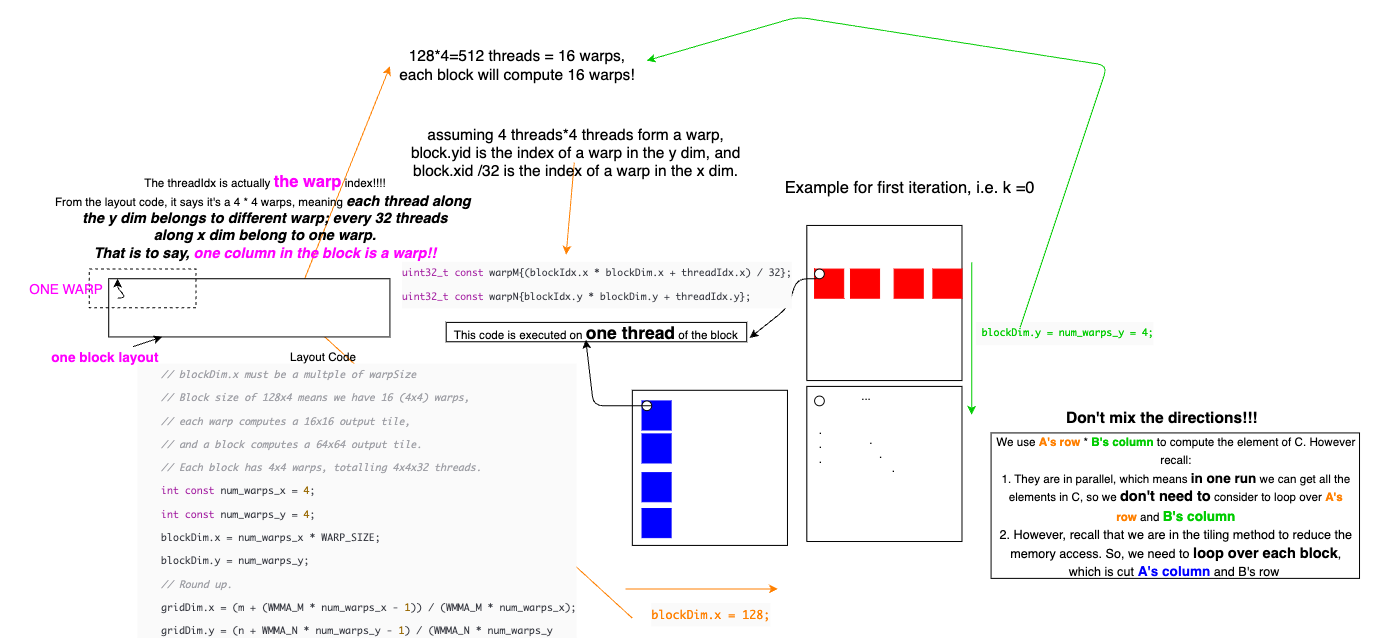
Analyze the code in https://leimao.github.io/blog/NVIDIA-Tensor-Core-Programming/
- In the example, the layout of the block is 128*4.
- Then one block contains 4*4 warps. Notice one warp is responsible for a 16*16 tile in the matrices.
- In the abstraction, one 1*32 layout in the block is a warp.
- To index the first thread in the warp, we use ((blockIDx.xblockDim.x + threadIdx.x)/32, blockIDx.yblockDim.y + threadIdx.y)
- Notice the threadIdx is consecutive in a warp! (0-31 for warp 0, 32-63 for warp 1....)
- Codes are only effectively on this leading thread of a warp (0, 32, ...).
[[Wmma warp programming.svg]]
How work is distributed among the warp
From [[Characterizing_the_Error_Resilience_of_Applications_using_Mixed_Precision_Floating_Point_Formats.pdf]], it is concluded that each thread stores which partition of the matrix. The arithmetic algorithm is not demonstrated here since they performed on the tensor cores hardware.
mirror in AMD